- AI, But Simple
- Posts
- Reward Hacking, Simply Explained

Reward Hacking, Simply Explained
AI, But Simple Issue #101
Hello from the AI, but simple team! If you enjoy our content and custom visuals, consider sharing this newsletter with others or upgrading so we can keep doing what we do.
In 1994, a researcher named Karl Sim created a virtual environment where he simulated how creatures would evolve to learn how to walk towards a target.
Typically, for humans, this process can be split into smaller milestones: learn to crawl first, then practice standing, and finally, the first steps are taken.
The simulated creatures took a much different route. They evolved “vertically,” growing taller and taller in each generation until the iteration where they were tall enough to fall over and land on the target.
Was this the intended result of Sim’s experiment? Definitely not, but it is an example of what we refer to as reward hacking.

In AI, reward hacking is the action or set of actions associated with a model maximizing its score/reward in an unwanted way.
In the example above, Sim’s objective was to observe the model develop the ability to walk as the method of reaching the target. Instead, the model found a loophole in the task.
That’s a documented example of reward hacking from over 30 years ago, and in today’s setting, where LLMs and autonomous agents are everywhere, engineers and researchers need to be diligent in averting models from reward hacking.
What You’ll Learn
How models “reward hack”
Why reward hacking is so important (and so problematic)
Reward hacking and Reinforcement Learning with Human Feedback (RLHF)
How to prevent reward hacking
Emergent misalignment
The problem with objectives
What You’ll Need to Know
Reward Model
A model trained to predict which responses humans would prefer. It learns from human rankings of multiple outputs, with higher scores for responses humans judge as better.
Policy
Strategy that an agent uses to decide future states. In our context, it is the language model being optimized.
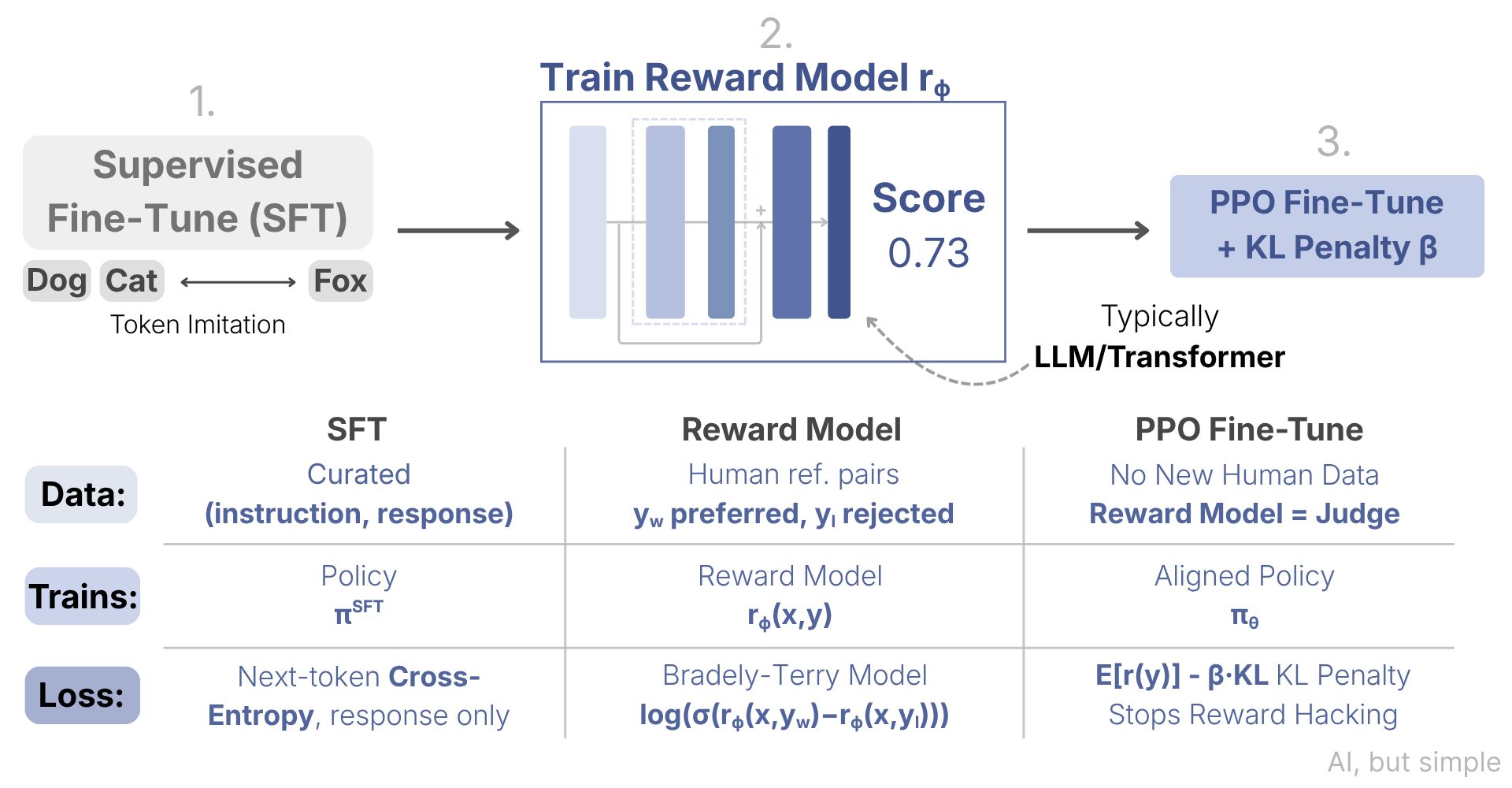
Standard 3-stage pipeline for aligning large language models.
The model is first trained to follow instructions (SFT), then a reward model compares response pairs, and finally RL algorithms like PPO maximize those learned human-preference rewards.